OpenAI vs Stack Overflow: Will this go to court?
Can Stack Overflow Fight Back? The Legal Case Behind Its Decline
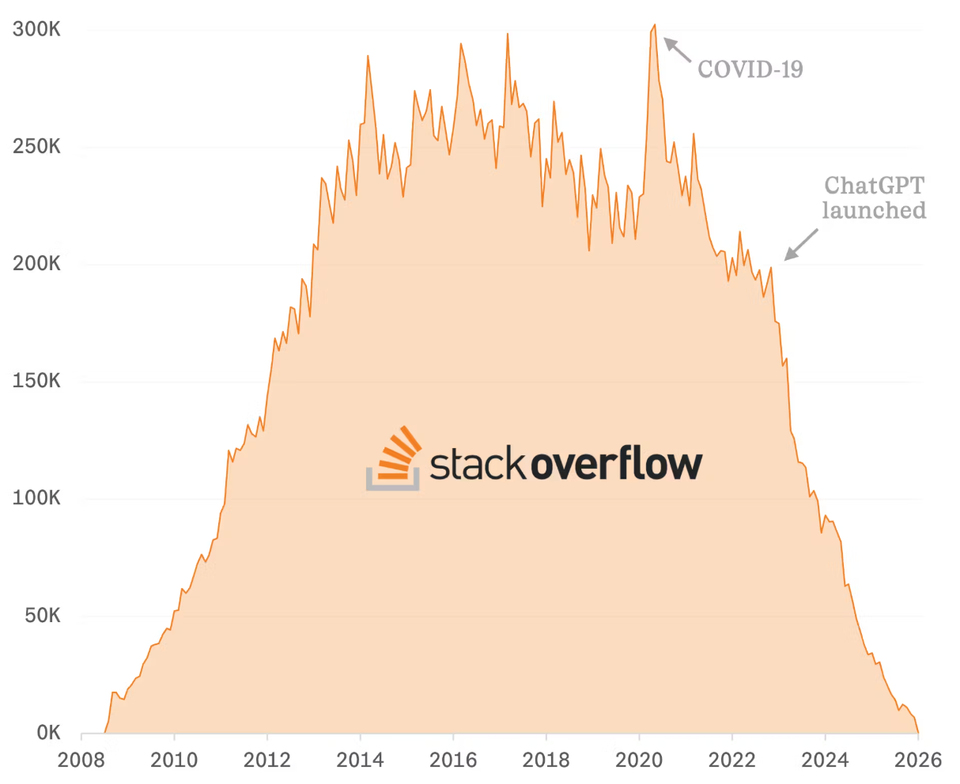
For years, Stack Overflow was the default problem-solving layer of the internet for developers. If you Googled an error message, chances were the answer lived there. Today, that behaviour has changed almost entirely. Developers are no longer searching for answers. They’re generating them.
In December 2025, Stack Overflow saw an estimated 78 percent year-on-year drop in new questions. While much of the discussion has focused on why developers are leaving, a more interesting question is emerging:
Does Stack Overflow have a legal case against the AI companies that replaced it?
From Knowledge Commons to Training Data
Modern coding assistants didn’t appear in a vacuum. Tools like GitHub Copilot, ChatGPT, and other large language models were trained on vast amounts of publicly available code and programming discussions. That training data almost certainly included years of Stack Overflow questions, answers, comments, and accepted solutions.
This creates a paradox:
- Stack Overflow invested heavily in building a moderated, high-quality knowledge base
- Millions of developers contributed expertise for free
- AI companies ingested that knowledge at scale
- AI tools now provide instant answers without sending users back to the source
In effect, the platform that curated the knowledge has been bypassed by systems that absorbed it.
Is This Just “Fair Use” or Something More?
AI companies typically argue that scraping public data for model training falls under fair use or similar doctrines, especially when the output is “transformative.” But that argument becomes less comfortable when the output directly replaces the original service.
Stack Overflow didn’t just lose traffic. It lost function. If developers can ask their IDE a question and receive an answer synthesized from years of Stack Overflow content, the original incentive to visit, contribute, or even exist diminishes.
This raises uncomfortable questions:
- If AI-generated answers are derived from community-generated content, who benefits?
- Should platforms that supplied the data receive compensation?
- At what point does “learning from the web” become commercial exploitation?
These questions are no longer theoretical. They cut to the core of how AI companies built competitive advantage so quickly.
Why Moderation and Culture Still Matter
AI isn’t the sole reason for Stack Overflow’s decline. The platform’s strict moderation style and emphasis on “perfect” questions made it increasingly unwelcoming to newcomers. That friction pushed users away long before AI tools fully matured.
But here’s the twist: AI tools succeeded partly because they removed that friction. You can ask a “bad” question, an incomplete question, or even the wrong question and still get a useful answer.
Ironically, AI inherited the answers without inheriting the community responsibilities.
The Precedent Problem
If Stack Overflow were to pursue legal action, the outcome would extend far beyond one website. A successful challenge could:
- Force AI companies to license training data
- Establish compensation models for community-driven platforms
- Redefine what “public data” means in the age of generative AI
A failed challenge, however, would send an equally powerful signal: that building a public knowledge platform also means surrendering it as future training data.
The Bigger Picture
Stack Overflow’s decline isn’t just about developers moving on. It’s about a shift in how value is extracted from the open web.
The platform may no longer be the place developers ask questions, but it remains one of the most influential sources of programming knowledge ever created. Whether that legacy can be defended, monetised, or protected in an AI-first world is still an open question.
What’s clear is this:
AI didn’t just replace Stack Overflow. It was built on top of it.
And the courts may eventually decide whether that matters.
Member discussion